Cassandra NoSQL Database
Summary
- Distributed NOSQL database
- No master / single point of failure / every node is equal (seed nodes are a small exception to this)
- Supports multi data centre replication
- Read and write scale linearly with number of nodes
- Consistency is configurable
- Stores data in sparse rows (not all rows need to have all columns like in a Map). Rows are partitioned (assigned) to different nodes to allow scaling.
- Optimized for writing not reading
- Good if you have very few types of queries and can optimize your tables for the queries. Recommendation is to first think of your query, then build a data model for it
- Open source
- Was created at Facebook
Links
- https://cassandra.apache.org/doc/latest/index.html
- https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/cassandraAbout.html
- https://en.wikipedia.org/wiki/Apache_Cassandra
- https://www.oreilly.com/library/view/cassandra-the-definitive/9781098115159/
Start Cassandra
Download from their website
I doubt anybody does this, but unpack the archive and run cassandra -f, done. Does not need any configuration to be tested
Run Cassandra in Docker
Run a single node DB via docker (can be accessed via localhost 9042). Add -d to run in the background
Or start your own cluster (found on https://gokhanatil.com/2018/02/build-a-cassandra-cluster-on-docker.html)
Once it runs, add more nodes with the IP of the the first one. One of the nodes is even in a different data center
docker run --name cas2 -e CASSANDRA_SEEDS="$FIRST_IP" -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter1 cassandra
docker run --name cas3 -e CASSANDRA_SEEDS="$FIRST_IP" -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter1 cassandra
docker run --name cas4 -e CASSANDRA_SEEDS="$FIRST_IP" -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter2 cassandra
Cassandra Cluster Manager
A script to create, launch and remove an Apache Cassandra cluster on localhost: https://github.com/riptano/ccm
Use Cassandra
cqlsh
Tool that comes with Casssandra so you can execute queries manually. Comes with a HELP command.
WebUi
There is also a web UI frontend for Cassandra: https://hub.docker.com/r/delermando/docker-cassandra-web
docker run --name cassandra-web -e CASSANDRA_HOST_IP="$FIRST_IP" -e CASSANDRA_PORT=9042 -e CASSANDRA_USERNAME=cassandra -e CASSANDRA_PASSOWRD=cassandra -p 3000:3000 delermando/docker-cassandra-web:v0.4.0
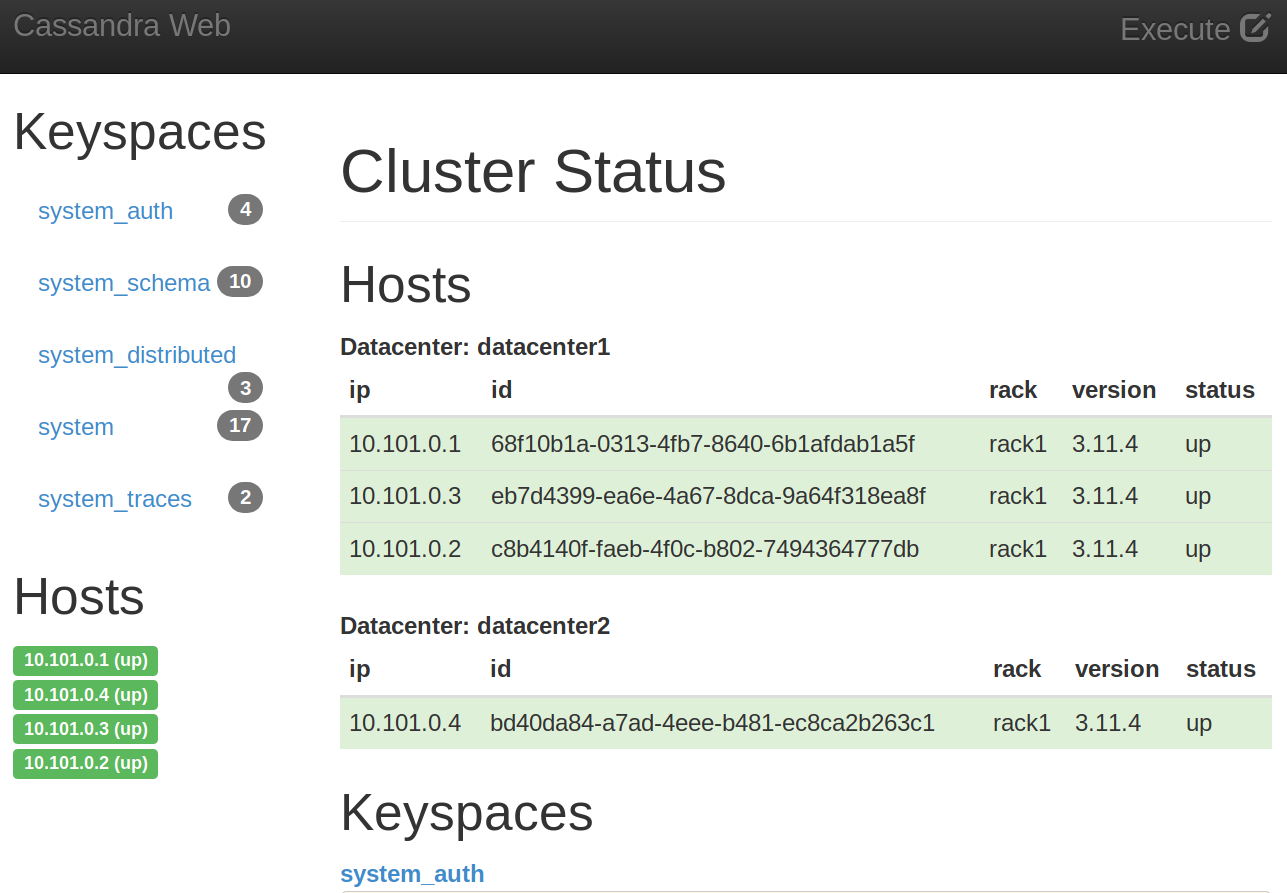
We will be accessible at http://localhost:300 and should look like this
Primary Key
Cassandra uses composite keys to access data. It consists of
- A partition key used to understand which server has the data
- clustering columns for accessing data quickly on a server and also keeping them sorted
As an example imagine you need to store some data based on post address. You can use
PRIMARY KEY (country) and your data would be distribute on the Cassandra servers using the country, data with the same country is stored together on one or multiple servers. So reading all the data of one country can be done by using only one Cassandra server.
PRIMARY KEY ((country, zip_code)) and the data with same zip code and same country stays together.
PRIMARY KEY ((country, zip_code), street, number) and data with country and zip code stays together, on top the data is sorted by street and number of the house. Also you can filter fast for data using all of this
In the example (country, zip_code) is called a composite partition key (to partition data between servers and composite because we use more than one column) and street, number is the Clustering Key (to make filtering inside the table fast, like an index in an normal SQL table).
See also https://www.baeldung.com/cassandra-keys
ALLOW FILTERING / Secondary Indexes
Cassandra does not allow you per default to query data without the partition key. Otherwise each query would need to be send to all nodes and wait for all of them to return a result. You can overwrite this with the ALLOW FILTERING KEYWORD but you should rather thing about if your data model should not be changed.
https://cassandra.apache.org/doc/latest/cassandra/cql/indexes.html
An alternative would be to create an secondary index on the column you want to filter on. But that only works well if the column you add the filter on has neither too many different values nor too few and there are not a lot of updates or deletes on the column. So they are more like a hack if you did not foresee a query when designing the data model.
See also https://cassandra.apache.org/doc/latest/cassandra/cql/mvs.html
Another alternative might be Materialized views https://www.datastax.com/blog/allow-filtering-explained
Queries
Understand your cluster
SHOW VERSION;
Get all keypspaces (databases)
Get all tables
Creating data structures
Create a keypsace where all the data is stored at least twice in datacenter1 and at least once in datacenter2
WITH replication = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 2,
'datacenter2' : 1
};
Create a keyspace where all the data is stored at least on 2 nodes
WITH replication = {
'class': 'SimpleStrategy',
'replication_factor' : 2
};
Create a simple table (you can use describe table of an existing tables to see examples for the create table command)
id INT PRIMARY KEY,
name text
);
Data
INSERT INTO keyspacetest2.people (id, name) VALUES(2, 'Doe');
INSERT INTO keyspacetest2.people (id, name) VALUES(3, 'Jane');
INSERT INTO keyspacetest2.people (id, name) VALUES(4, 'Frank');
Have complex types in a column
INSERT INTO keyspacetest1.people2 (id,name,email) VALUES(1, 'John',['test@example.com', 'test2@example.com']);
UPDATE keyspacetest1.people2 SET email=email+['foo@example.com'] WHERE id=1; // ["test@example.com","test2@example.com","foo@example.com"] John
You can have a static column whose value is shared between all rows that have the same partition key.
Paging
You can use LIMIT to restrict the maximum number of rows return (but then there is no way to read the remaining ones) or use PAGING to make the client fetch automatically only a certain amount of rows and request more once you consumed them. In the Java client you can also manually do fetchMoreResults() before you consumed all of them to avoid extra latency.
TTL
Deleting is something expensive in Cassandra. If you already know that your data has to be deleted after some time adding a TTL is much better because then all nodes either have the data with TTL or never have it.
SELECT TTL(name) FROM keyspacetest2.people;
Transactions
Inserts and Updates can be done conditionally
UPDATE ... IF active='true'
This is also available in the Java prepared statement .ifNotExists()
The consistency level for such statements is by default stricter.
You can also group statements into a BATCH, which makes them slower but ensures they are all executed together, see also https://www.baeldung.com/java-cql-cassandra-batch
Counters
Allows you to count something, value can only be incremented or decremented. Can not be part of the primary key and if you use a counter, everything but the primary key has to be counters
UPDATE keyspacetest2.demo SET visits=visits+1 WHERE id=...;
Java Integration
There are several java clients http://cassandra.apache.org/doc/latest/getting_started/drivers.html#java
Cassandra datastax java
https://github.com/datastax/java-driver
final CqlSessionBuilder builder = CqlSession.builder();
builder.addContactPoints(nodes);
builder.withLocalDatacenter("NameOfYourDataCenter");
session = builder.build();
final Relation relationA = Relation.column(partitionColumn).isEqualTo(bindMarker());
final Relation minDate = Relation.column(clusterColumn).isGreaterThanOrEqualTo(bindMarker());
final Relation maxDate = Relation.column(clusterColumn).isLessThanOrEqualTo(bindMarker());
Select query = QueryBuilder
.selectFrom(myPartitionKey, myClusterKey)
.column(myDataColumn)
.where(relationA)
.where(minDate)
.where(maxDate);
PreparedStatement statement=session.prepare(query.build());
BoundStatement bound=statement.bind("A", now, later);
final RegularInsert insert = insertInto(myPartitionKey, myClusterKey)
.value(myDataColumn1, bindMarker())
.value(myDataColumn2, bindMarker())
);
PreparedStatement statement2=session.prepare(insert.build());
session.execute(statement2.bind("A", "B"));
Maintain Cassandra
Cassandra exposed its current status via JMX (which I found hard to access depending how and where you run Cassandra), nodetool (which is an internal tool that comes with Cassandra and you can also have a Prometheus exporter (which puts everything behind one key with lots of labels)
Nodetoool
Watch out, the nodetool command only talks to one Cassandra node, even if some commands return also data from other nodes.
How to start the command
nodetool -u cassandra-superuser -pw secret status
docker exec -ti cas1 nodetool status
Understand how your cluster is organized
Health of your cluster
How is the node doing you are connected to
How Cassandra distributes data between the nodes (not so interesting)
Cluster statistics
Table statistics
Write data to disk nodetool flush
Deletes data that the current node does not need any more because another node took over ownership (you need to do this every time you add a new node to the cluster) nodetool cleanup
Check the cluster for problems and fix them. As this takes a while, by default the repair is incremental, data that has already been checked and fixed is separated from the unchecked data so the process continue where it stopped last time. If you use secondary indexes it is recommended to rebuild them after a repair. netstats shows the progress of the repair. You can also restrict the repair to the local datacenter.
nodetool repair --in-local-dc
nodetool --full
nodetool --pr
nodetool netstats
nodetool rebuild_index
There is also an extra tool, the Reaper, to have automated regular repairs http://cassandra-reaper.io/
Cassandra comes with several tool starting with sstable* to fix the SSTables where all the data is stored eventually.
Add a new node
This is unfortunately a very manual process
- Add the new node
- Wait until compaction on is done (easily takes days and needs a lot of disk space on the new node)
- Run cleanup on all the other nodes one by one (needs a lot of disk space)
- Again check when they are done (easily takes days)
- Remove snapshots or else you do not safe disk space
Backups
On every node you can create a snapshot which creates hardlinks on the filesystem. You most likely want to run this at the same time on all nodes https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/tools/toolsSnapShot.html
nodetool listsnapshots
nodetool clearsnapshot --all
There is a tool called Medusa https://github.com/thelastpickle/cassandra-medusa/blob/master/docs/Performing-backups.md which automates the creation of snapshots and upload and restore for you.
Performance tuning Cassandra
- Each node should have
- max 1TB data size
- 32GB memory
- 8 cores
- Either SSDs or data and commit log should be on different disks
- correct date and time (use ntp)
- In Azure cloud Premium SSDs
This is a very good tool to see current performance on one node, for example that 95% of all read requests were faster than 228 ms while 95% of all write requests were faster than 943 micro seconds
Percentile Read Latency Write Latency
95% 223875.79 943.13
You can also get the same for a specific table
General performance
- Check that there is no repair, cleanup, compaction etc. is running
- Check CPU load and IO if the server is busy doing something else
- Did you reach the CPU limits, either the real ones are limits e.g. from Kubernetes
- Are all nodes up and running
- https://tobert.github.io/pages/als-cassandra-21-tuning-guide.html
How to improve read performance
- Caches
- Key Cache might help if you query the same things multiple times (enabled by default)
- Row cache even saves you from reading it from disk again but once you write to a partition all rows from that partition are flushed from the cache which makes it less useful. So not enabled by default
- Chunk cache Saves you from reading chunks from the disk and uncompress them and that stays useful even if more chunks have been written afterwards. It is enabled by default.
- Use nodetool info to see if the caches work
Key Cache : entries 12261, size 4.43 MiB, capacity 100 MiB, 14353 hits, 26200 requests, 0.548 recent hit rate, 14400 save period in seconds
Row Cache : entries 0, size 0 bytes, capacity 0 bytes, 0 hits, 0 requests, NaN recent hit rate, 0 save period in seconds
Counter Cache : entries 0, size 0 bytes, capacity 50 MiB, 0 hits, 0 requests, NaN recent hit rate, 7200 save period in seconds
- Bloom Filter
- Reduce the risk for false positives, but requires then more memory
- Use the LeveledCompactionStrategy which ensures each row is only in one SSTable. But that crates extra IO to move data around.
- Use the TimeWindowsCompactionStrategy if all your data has a TTL
- The concurrent_reads setting should be number of disks we use x 16. If it is higher the reads wait for the disk
How to improve writes
- Memtables
- Make it bigger
- Allow more threads to write
- Commit logs
- Make them bigger
- Put them on a different disk than the data - or use SSD
- Use SizeTieredCompactionStrategy (default)
- The concurrent_writes setting should match the number of parallel writes we expect
Cassandra Internals
Consistency
| Strict consistency | Causal consistency | Weak consistency / Eventual consistency |
| Any read returns what what the very last write put into the DB. This is what you want but also what is hard to get for distributed DBs | Write events that are not unrelated to each other have to stay in the correct order for all nodes | All writes are executed on all nodes but it might take some time until the correct result is everywhere |
In Cassandra you can choose the consistency with write operations to choose between speed and consistent results. If you need strict consistency use LOCAL_QUORUM for reading and writing.
See also https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/dml/dmlConfigConsistency.html
In CQLSH you can change it like this
CONSISTENCY LOCAL_ONE;
In the Java driver
s.setConsistencyLevel(ConsistencyLevel.LOCAL_TWO);
Cassandra Terminology
- column: A key / value pair, e.g. Name -> Thorsten
- row: container for several columns. Not all rows need to have the same columns. Each row is found via a primary key
- partition: Groups several rows together on one or more servers
- table: All the rows in all the partitions
- keyspace: Multiple tables
- cluster: One or more servers having several keyspaces
- node: One running instance of Cassandra
- cluster: Several nodes
- datacenter: Several nodes that can exchange data fast and cheap
- Column: The basic data structure of Cassandra with column name, column value, and a time stamp
- SuperColumn: Like a column but its values are other columns. The can improve performance if you group columns in a SuperColumn that you often read together
- Column Family / table: A table with columns and rows. The rows are free to not have all the columns
- keyspace: Like a database, groups several column family
Gossip protocol
Once per second a random Cassandra node receives a ping like message it has to respond are the sender marks it as down.
Snitches
Make Cassandra understand how its node are distributed, e.g. if they are close to each other. The default is the SimpleSnitch but it does not understand Racks and Datacenters. There are others that use manual property files to understand your topology, the IP address, based on timings or using cloud provider internals.
Recover from non sync data
Hints
When a node is down for a short amount of time, other nodes collect all to be written data for that node so if it comes back soon that is easier to apply then a full sync of the node
Read repair
If you read through your consistency level from more than one node, Cassandra will notice if their response differs and fix this then for you
Anti Entropy Repair
You can also start a manual repair through nodetool sync all servers again
Merkle Tree
Tree structure where the leaves contain an hash value for the Cassandra data blocks and the parent of the leaves are hash values for all the child nodes. Effective way to compare data between nodes.
How writing works
- Client sends data to the node that serves as coordinator for the write request.
- Coordinator calculates which nodes need to store the data
- All the nodes in the local datacenter get the data directly
- If there are other datacenters, data is send to the coordinator in each datacenter
- Node receives data
- Writes to commit log (only used if node crashes before the following steps are done)
- We consider write to be successful
- Write data to Memtables (in memory)
- If Memtables are big enough data is flushed to SSTables (on disk)
- Commit log no longer needed
- Data in SSTables are only appended, there is not modification
- Cassandra may merge internally SSTables and also removing obsolete data doing so (compacting)
- You can also enable compression (like zip)
How reading works
- Client can connect to any node, either the node has the data or it acts as coordinator
- Reads are slower because Cassandra appends all changes and deletes and this has to be resolved during read (not a problem if you never modify data)
- The read is send to the fastest node
- Depending on the consistency level more additional nodes also get the read request, only that they will only send a hash of the data and not the data itself
- The hash and the actual data we get is compared, if it matches the read is ok, if not a Read Repair is done
- In the Read Repair data is read from all nodes and the one with the newest timestamps will be written to all the others
- In each node first the Row Cache is checked, if it contains result, return it
- If we are lucky data is in the Memtables
- Otherwise we use a Bloom filter, that can tell is that data is NOT in the SSTables (but is is still unsure if it really is there)
- If Bloomfilter can not exclude it, try the Key Cache if we already know where in the SSTables the data is
- If Key Cache does not have it, a index of the SSTable is used to find the data
- We only need to really load the chunks of data from disk if it is not in the chunk cache
How deleting works
Instead of deleting data, it is marked with a tombstone for 10 days like a soft delete. This helps to understand if data is missing because it was deleted or if data is missing because the write has not yet propagated. As node could be down for some time that would be otherwise a risk
| Node A | Node B | conclusion |
| data | no data | B needs to get data from A |
| data | data + tombstone | B missed the delete and needs to add tombstone |
- Putting null into an existing field is like a delete. Too many nulls create too many tombstones (avoid!)
- Delete the biggest thing possible, so the whole partition, not all the rows.
- Replacing a list in a field also creates a Tombstone
- Use TTL when inserting instead of deleting later
Caching
key cache: Cache of partition keys -> rows index (enabled by default) row cache: Cache of entire rows chunk cache: Cache of uncompressed chunks of data counter cache: Cache of counters (enabled by default)
Bootstrapping
When you add a new node it contacts a so called seed node to read all the data from. It is recommended to have 2 seed nodes per data center